あなたのポケットデータサイエンティスト。NEXSPCは「データ収集」と「データ分析」の境界を取り払います。従来、エンジニアはデータをExcelやMinitabにエクスポートして分析していましたが、これは時間がかかりミスも起きやすい作業でした。私たちは数理統計エンジンをシステムカーネルに直接組み込みました。会議室でも生産現場でも、ブラウザを開くだけで、回帰分析、仮説検定、分散分析(ANOVA)などの専門ツールを呼び出せます。データ駆動型の意思決定を、Web閲覧のように簡単に。
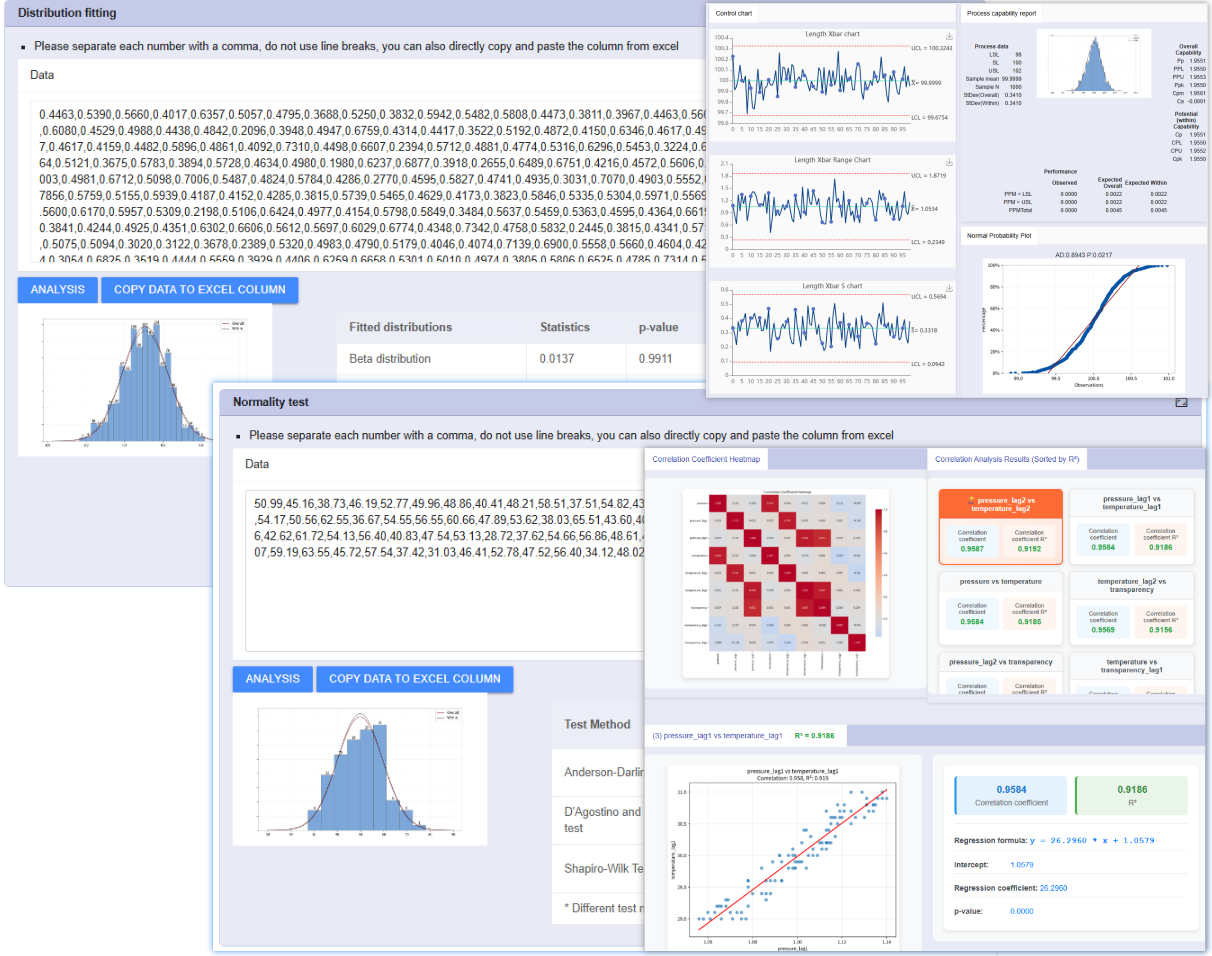
CPK/PPKシミュレーションツール
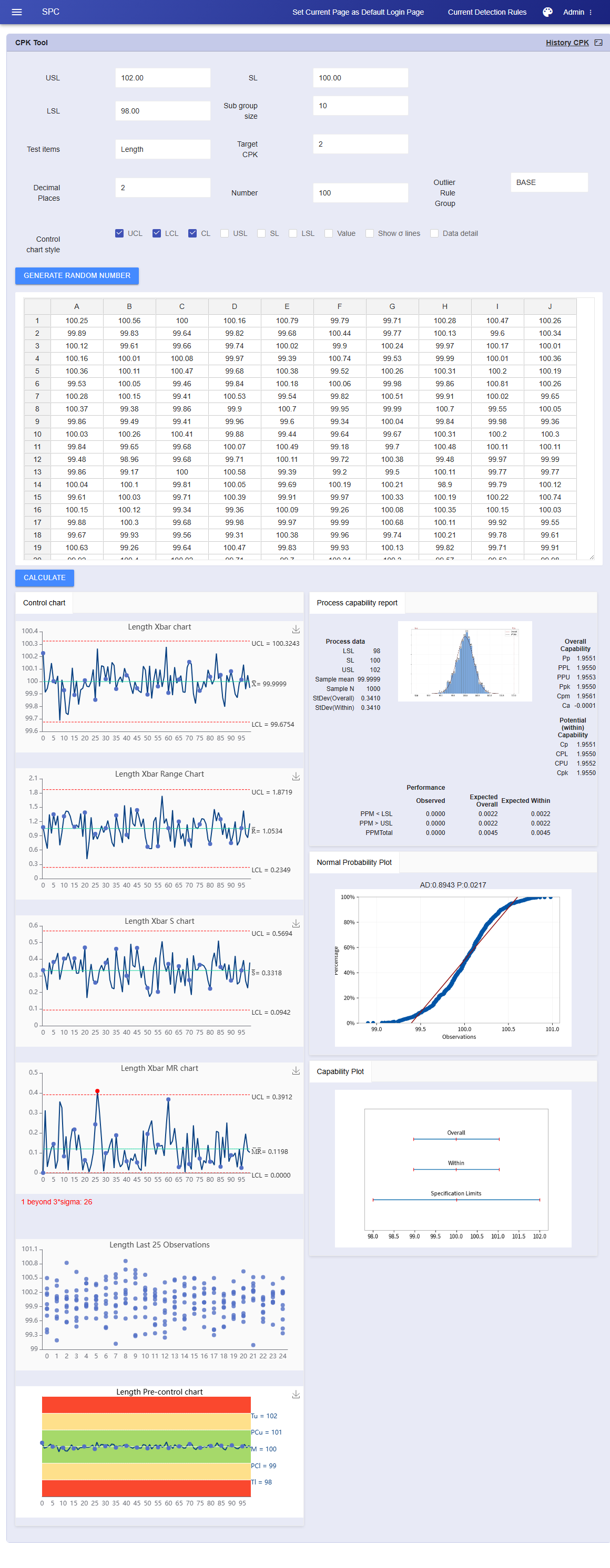
Excelデータはあるけれど、プロジェクト作成や複雑なシステム設定は面倒...すぐに専門的なSPCレポートが見たい。そんな時は、Excelから1列または複数列のデータ(サブグループの有無にかかわらず)をコピーして入力ボックスに貼り付けるだけ。システムがフォーマットをスマートに認識し、詳細なSPC分析レポートを即座に生成します。
管理図、ヒストグラム、正規性検定、工程能力図、レインボーチャートなどの多次元チャートを一括生成します。
単一データ:I-MR管理図、直近25点の観測値、工程能力分析を自動出力。
サブグループデータ:Xbar-R / Xbar-S管理図を自動出力。
この「コピー即分析」モードは作業時間を90%短縮し、従来のMinitab 6-in-1レポートを遥かに凌ぐ豊富なチャートを提供します。
教育用データが必要ですか?あるいは「CPK=1.67の時、管理図はどう見えるか」を検証したいですか?
業界初のデータ逆生成エンジン。データを受動的に分析するだけでなく、データのあり方を能動的に定義できます。
規格限界(USL/LSL/Target)、サブグループサイズ、データ点数、小数点以下の桁数を自由に指定可能。
目標とするCPK値(例:1.33や2.0)を入力するだけで、アルゴリズムがその能力レベルに合致するランダムな正規分布データを自動生成します。
生成されたグラフに満足できない場合(例:もっと多くの異常値/外れ値を見たい)、完璧なシミュレーションデータが得られるまで「再生成」をクリックするだけです。
実測データもシミュレーションデータも、ワンクリックでExcelにエクスポート可能。生データだけでなく、分析結論やチャートも完全に保持されるため、二次編集や正式な品質システム文書としてのアーカイブに最適です。
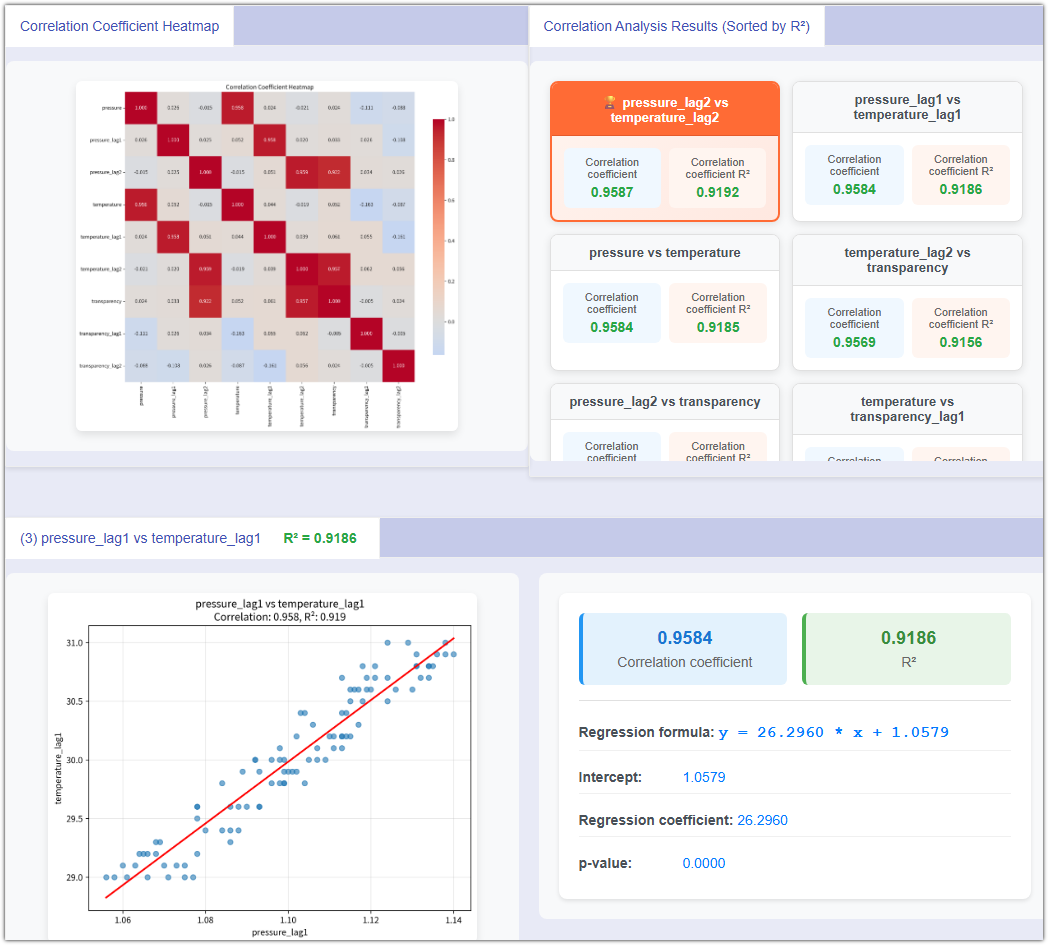
Regression & Correlation Analysis
「直感」から「定量化」へ、品質低下の真犯人を特定します。歩留まりが変動した際、結果だけでなく原因を究明します。NEXSPCは強力な多次元相関マイニングエンジンを提供。面倒なデータのエクスポートやクリーニングが必要な従来ツールとは異なり、データベースを直接呼び出します。特に「自動ラグ(Auto-Lag)」アルゴリズムを導入し、複雑なプロセスパラメータ(温度、圧力など)と品質特性(寸法、硬度など)の間に潜む、「時間差」に隠れた関係性を正確に特定します。
「エクスポート-クリーニング-インポート」の悪夢にさようなら。Excelシートを整理する必要はありません。メニューから既存の検査項目を選択するだけで、システムが履歴データを即座に取得し、整列(アライメント)して分析します。データフローの障壁をゼロにし、分析を呼吸のように自然なものにします。
「プロセス遅延」を解決する高度な技術です。多くの場合、温度上昇は即座に硬度低下を引き起こさず、2時間のタイムラグが発生します。NEXSPCはラグ(遅延)サイクルの設定をサポート。システムは自動的に計算を反復(T-1, T-2... T-N)し、相関係数(R)が最も高い時間差を特定。「現在の調整」がいつ「未来の品質」に影響するかを解明します。
変数(ラグ変数を含む)の相関係数ヒートマップを自動描画し、変数間の相関関係を直感的に可視化します。
回帰方程式、R二乗(決定係数)、P値を自動計算。変数間の「因果関係」が統計的に有意であるかどうかを、厳密な統計言語で提示します。
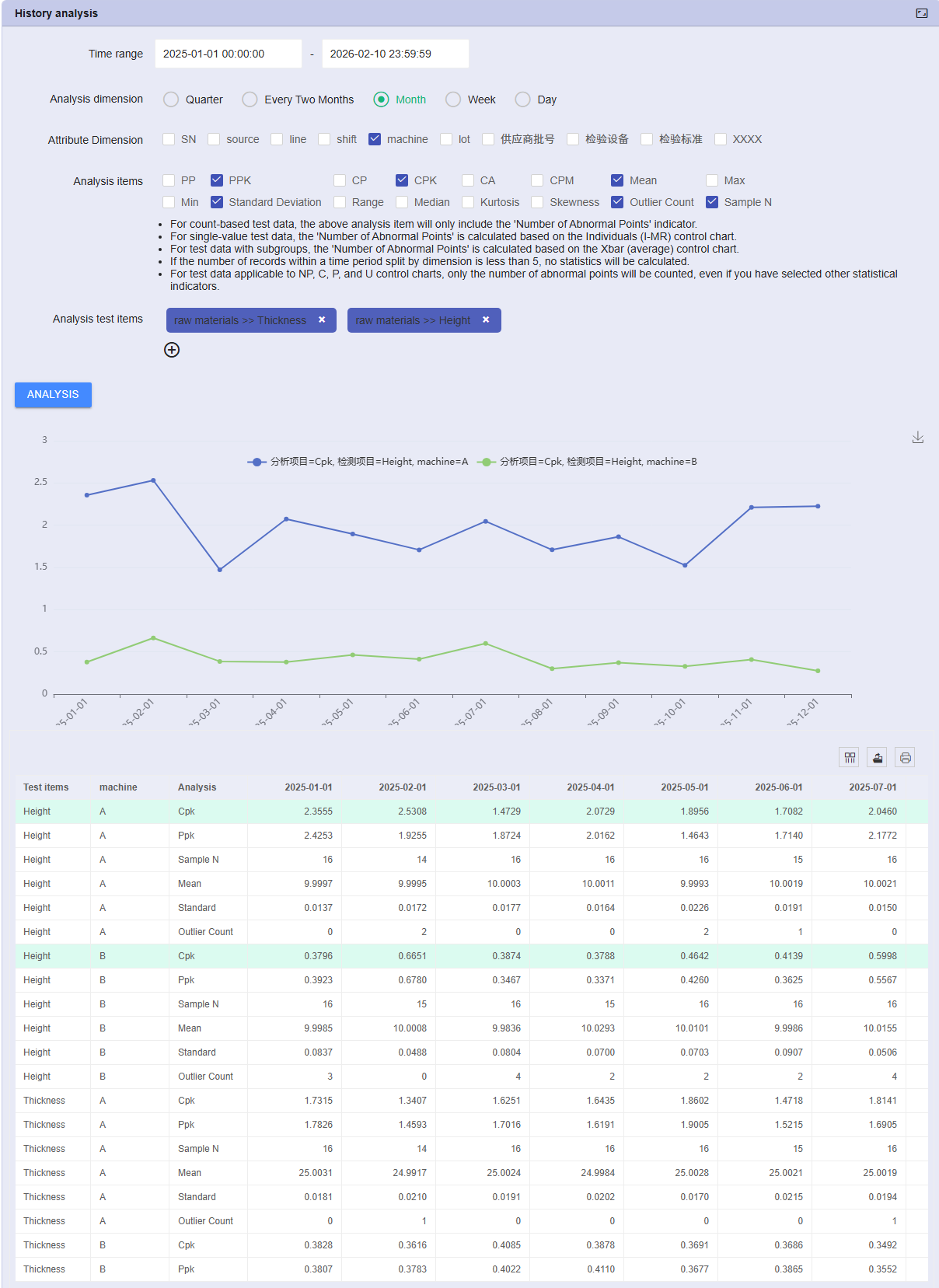
History Trend Analysis Engine
10項目の年間品質変化をどう迅速に集計するか?従来の方法では悪夢でした。大量のデータをエクスポートし、月ごとに手動で分割し、個別にCPKを計算してグラフ化する...。NEXSPCは強力な「時系列スライシングエンジン」を内蔵し、数日間の作業を数秒に短縮します。分析サイクルを定義するだけで、データのクリーニング、分割、指標の集計(アグリゲーション)が自動化され、長期的な品質安定性分析が呼吸するように自然に行えます。
シナリオ:Q1対Q2の品質比較、あるいは重要寸法の月次CPK推移を確認したい場合。NEXSPCは手動データ処理のボトルネックを完全に解消します。Excelにエクスポートして月/週ごとに分割する煩わしさも、Minitabで分析を繰り返し実行する必要もありません。
データ自動集計(アグリゲーション): システム内にデータがある限り、期間が1年でも3年でも、瞬時にデータを取得・集計します。
多項目並行分析: 複数の重要管理項目(KPC)を同時に選択可能。履歴分析を一括実行し、「検査項目が多すぎて処理しきれない」という問題を解決します。
シナリオ:異なる管理階層のニーズに合わせて分析の粒度(Granularity)をカスタマイズ。シンプルな設定ウィザードで分析レポートを迅速に作成します。
項目選択: 関心のある検査項目を1つ以上チェックします。
範囲設定: 分析の開始日と終了日を設定(例:2026年1月1日〜2026年12月31日)。
サイクル分割: データのスライス粒度を選択。四半期、隔月、月、週、日ごとの自動分割に対応。
指標選択: PPK、CPK、Ca(正確度指数)、異常点数、平均値(Mean)、標準偏差(StdDev)などのKPIを自由に組み合わせ可能。
シナリオ:具体的な数値レポートを確認しつつ、経営層には直感的なトレンド折れ線グラフを提示したい場合。
分析完了後: システムは即座に多次元の品質履歴統計テーブルを生成します。
構造化レポート: 各期間(例:1月、2月...)のCPK値や異常点数などの指標を詳細にリストアップし、時間の経過に伴う品質の変化を明確に示します。
オンライントレンド作図: PPT作成のためにスクリーンショットを撮る必要はありません。Web上の表で行(例:「平均値」や「CPK」)を選択するだけで、動的なトレンド折れ線グラフを即座に生成。どの月の変動が最大か?どの週に平均値のドリフト(偏位)が発生したか?を直感的に把握できます。
シナリオ:分析結果を活用してPDCAサイクルを回す、あるいはより深い二次的なデータマイニングを行う場合。
ワンクリックExcelエクスポート: オンライン作図も可能ですが、生成された統計結果テーブルをExcelにエクスポートし、個別のレイアウト調整やアーカイブを行うことも可能です。
生産性の解放: エンジニアを低付加価値な「表作成」から解放し、データの背後にある原因究明に集中させます。「四半期品質レビュー」や「年間工程能力サマリー」を負担ではなく、継続的改善(PDCA)の出発点にします。
Hypothesis Testing / T-Tests
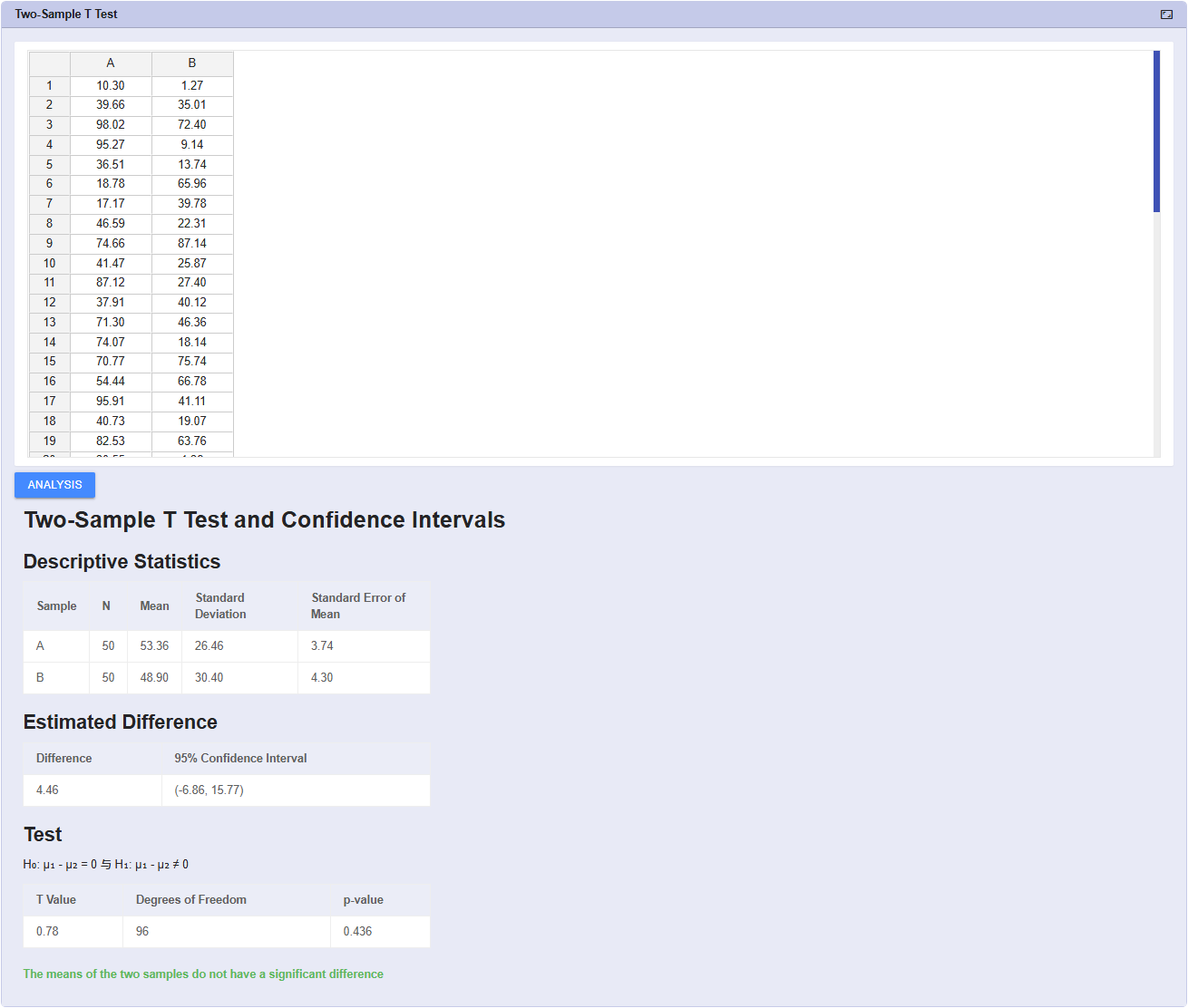
「改善」が運ではなく、有効であることをデータで証明します。PDCAサイクルの「評価(Check)」フェーズは極めて重要です。NEXSPCはあらゆるシナリオに対応したt検定ツールを提供し、改善前後の差異を科学的に比較します。
1標本t検定(平均値のズレを検証)および2標本t検定(機械A対Bの比較、または改善前後の比較)をサポート。
信頼区間(Confidence Interval)図と箱ひげ図を自動出力。2つのデータグループ間に「統計的有意差」があるかを明確にし、「見せかけの改善」を排除します。
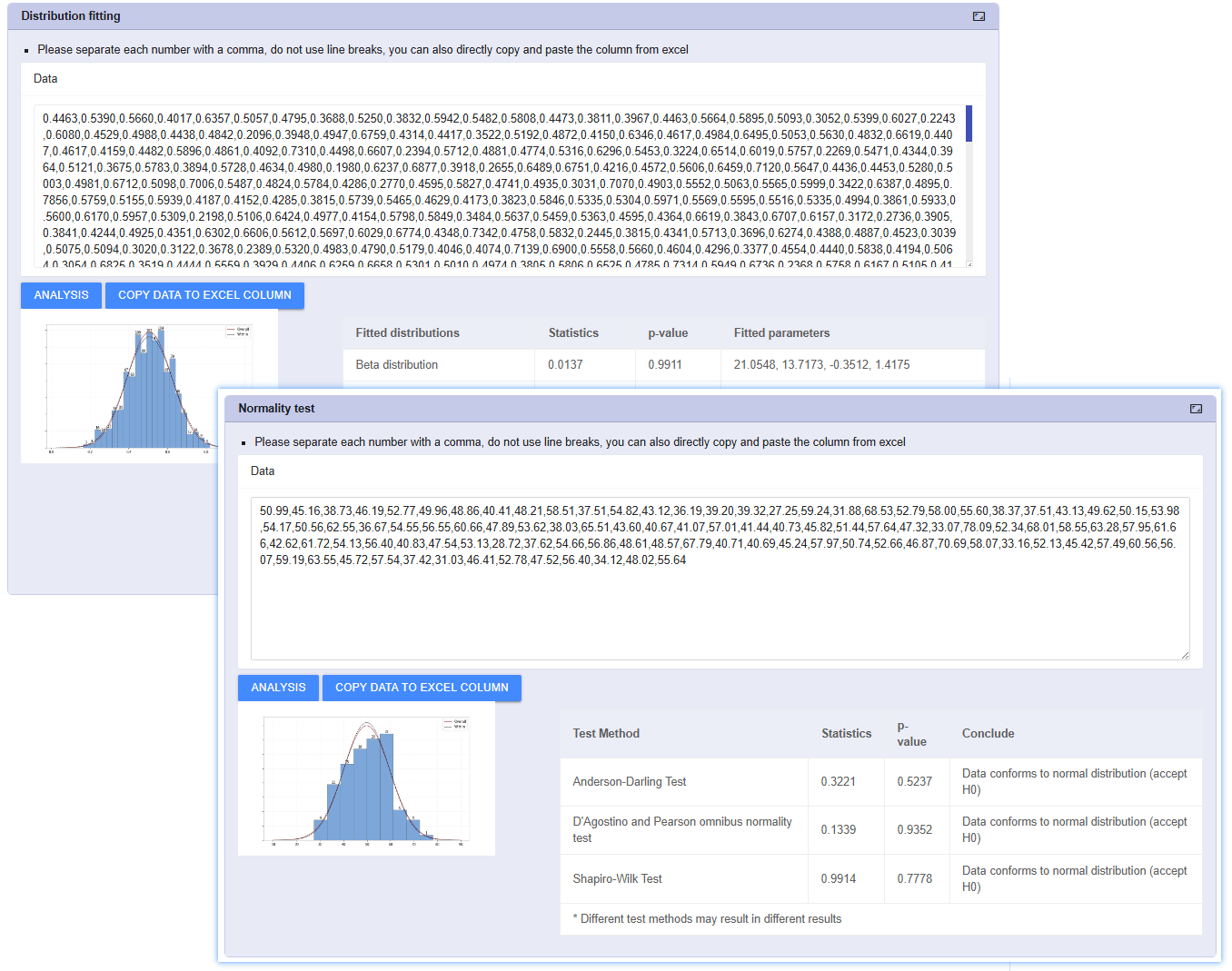
Distribution Fitting
現実世界を再現し、非正規データを正確に評価します。すべてのデータが完全な正規分布に従うわけではありません。寿命試験、平面度、不純物含有量などの歪んだデータ(Skewed Data)に対し、無理にCPK公式を適用すると深刻な誤判定を招きます。
ワイブル(Weibull)、対数正規、指数など多種多様な分布モデルを内蔵。Anderson-Darling検定を自動実行し、最も適合度の高い分布曲線を推奨します。
最適モデルに基づいて正確なPpk(工程性能指数)を再計算し、半導体や化学などの複雑な業界における分析精度を保証します。
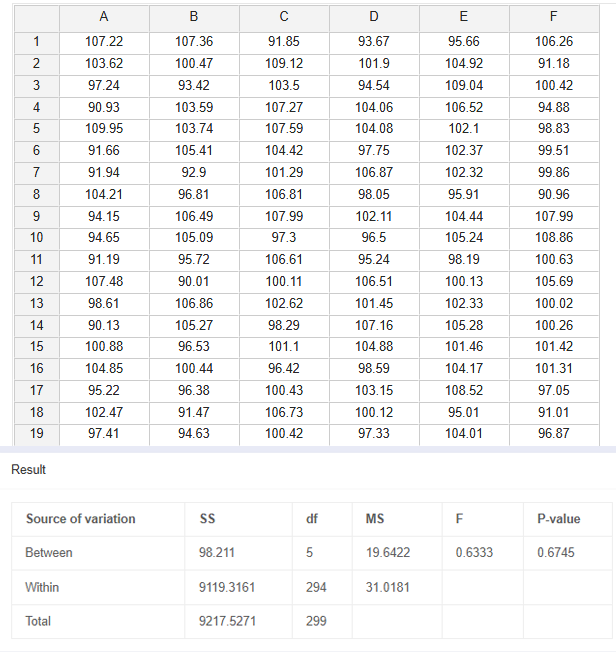
ANOVA & F-Test
層を剥がすように、多重干渉の中から変動源を特定します。品質影響要因が2つを超える場合(例:3つのシフトや4つの金型の比較)、単純なt検定では力不足です。
多群間の平均値に有意差があるかを迅速に特定し、主効果プロット(Main Effects Plot)を生成します。
平均値を比較する前に、2つのデータセットの変動幅(分散)が一致しているかを検証します。設備の精度安定性を判断するために極めて重要です。