आपका पॉकेट डेटा वैज्ञानिक। NEXSPC 'डेटा संग्रह' और 'डेटा विश्लेषण' के बीच की सीमा को तोड़ता है। पारंपरिक रूप से, इंजीनियर डेटा को एक्सेल या मिनिटैब में निर्यात करते हैं—जो समय लेने वाला और त्रुटिपूर्ण होता है। हम गणितीय सांख्यिकी इंजन को सीधे कर्नेल में एम्बेड करते हैं। बस एक ब्राउज़र खोलें और रिग्रेशन, परिकल्पना परीक्षण और एनोवा जैसे पेशेवर उपकरणों का उपयोग करें।
CPK/PPK सिमुलेशन टूल
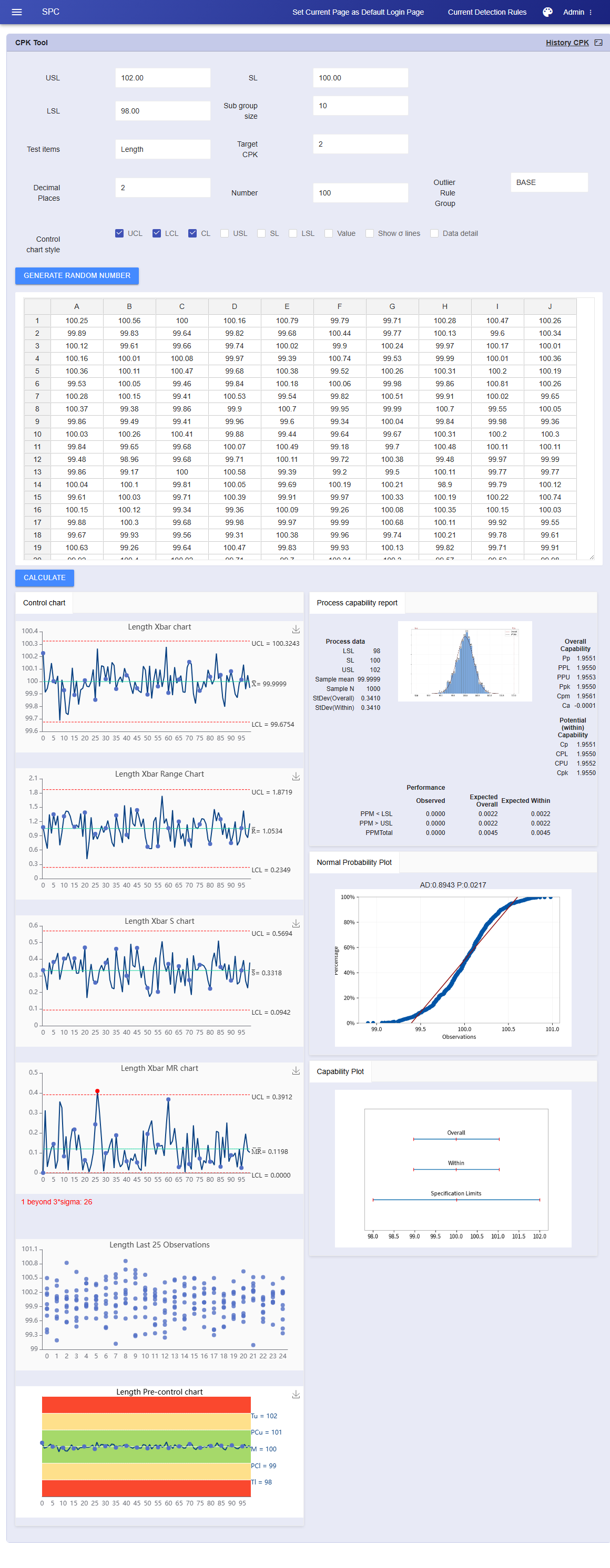
एक्सेल डेटा है लेकिन प्रोजेक्ट सेट नहीं करना चाहते हैं? बस एक्सेल से डेटा के एक या अधिक कॉलम (उपसमूहों के साथ या बिना) को सीधे इनपुट बॉक्स में कॉपी और पेस्ट करें। सिस्टम समझदारी से पहचानता है और एक गहन SPC विश्लेषण रिपोर्ट तैयार करता है।
एक बार में कंट्रोल चार्ट, हिस्टोग्राम, नॉर्मलिटी टेस्ट, प्रोसेस कैपेबिलिटी प्लॉट और रेनबो चार्ट जेनरेट करता है।
व्यक्तिगत डेटा: I-MR चार्ट ऑटो-आउटपुट करता है।
उपसमूह डेटा: Xbar-R / Xbar-S चार्ट ऑटो-आउटपुट करता है।
यह 'कॉपी-एनालाइज़' मोड 90% समय बचाता है, जो पारंपरिक मिनिटैब रिपोर्ट से कहीं बेहतर है।
क्या आपको शिक्षण डेटा की आवश्यकता है? या सत्यापित करने की आवश्यकता है कि 'CPK=1.67 होने पर नियंत्रण चार्ट कैसा दिखता है'?
उद्योग का पहला रिवर्स डेटा जनरेशन इंजन। डेटा का निष्क्रिय रूप से विश्लेषण करना बंद करें; सक्रिय रूप से डेटा के आकार को परिभाषित करें।
स्वतंत्र रूप से विशिष्ट सीमाएं (USL/LSL/लक्ष्य), उपसमूह आकार, डेटा बिंदु और दशमलव स्थान निर्दिष्ट करें।
बस अपना लक्ष्य CPK (जैसे 1.33 या 2.0) इनपुट करें, और एल्गोरिदम स्वचालित रूप से उस क्षमता स्तर से मेल खाने वाला यादृच्छिक सामान्य वितरण डेटा उत्पन्न करता है।
यदि उत्पन्न ग्राफ़ असंतोषजनक है (उदाहरण के लिए अधिक आउटलेयर देखना चाहते हैं), तो बस 'पुनः उत्पन्न करें' पर क्लिक करें।
एक्सेल में एक-क्लिक निर्यात का समर्थन करता है। फ़ाइल में कच्चा डेटा विवरण, विश्लेषण निष्कर्ष और चार्ट शामिल हैं, जो औपचारिक गुणवत्ता प्रणाली दस्तावेजों के रूप में संग्रह की सुविधा प्रदान करते हैं।
Regression & Correlation Analysis
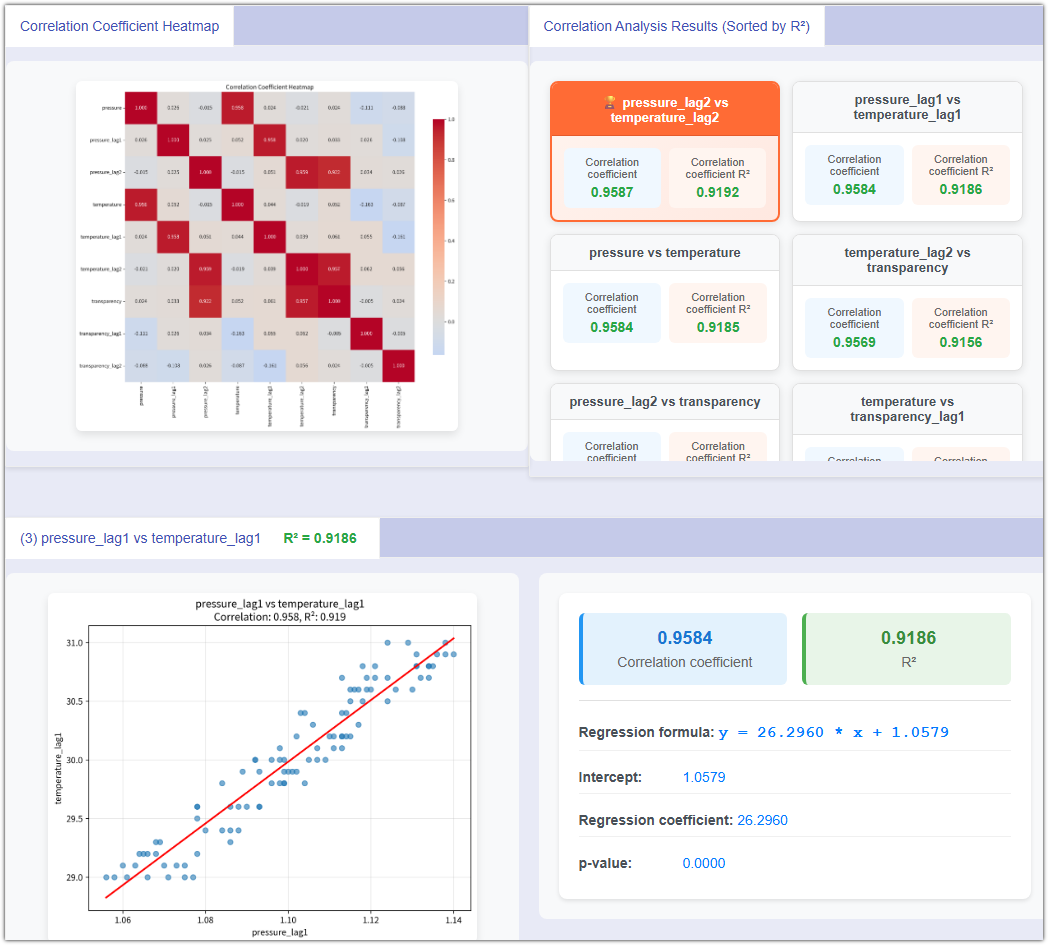
'अंतर्ज्ञान' से 'परिमाणीकरण' की ओर बढ़ें और गुणवत्ता के मुद्दों के मूल कारण को इंगित करें। NEXSPC एक शक्तिशाली बहु-आयामी सहसंबंध खनन इंजन प्रदान करता है। विशेष रूप से ऑटो-लैग (Auto-Lag) एल्गोरिदम का परिचय देता है, जो प्रक्रिया मापदंडों (तापमान, दबाव) और गुणवत्ता विशेषताओं के बीच 'समय के अंतर' द्वारा छिपाए गए संबंधों को सटीक रूप से लॉक करता है।
'निर्यात-स्वच्छ-आयात' दुःस्वप्न को अलविदा। एक्सेल शीट को व्यवस्थित करने की आवश्यकता नहीं है। बस मेनू से निरीक्षण आइटम चुनें, और सिस्टम विश्लेषण के लिए ऐतिहासिक डेटा को तुरंत संरेखित करता है।
'प्रक्रिया विलंबता' को हल करने के लिए उन्नत तकनीक। अक्सर, तापमान में वृद्धि से कठोरता में तुरंत गिरावट नहीं आती है - यह 2 घंटे तक पीछे रह जाती है। NEXSPC लैग/डिले चक्र सेट करने का समर्थन करता है। सिस्टम उच्चतम सहसंबंध गुणांक (R) के साथ समय के अंतर को खोजने के लिए स्वचालित रूप से गणना (T-1... T-N) करता है।
चर (अंतराल चर सहित) के लिए सहसंबंध गुणांक हीटमैप को स्वचालित रूप से प्लॉट करता है, जो सहसंबंधों को स्पष्ट रूप से प्रस्तुत करता है।
रिग्रेशन समीकरण, आर-स्क्वायर और पी-वैल्यू की स्वचालित गणना करता है। आपको बताता है कि क्या चर के बीच संबंध सांख्यिकीय रूप से महत्वपूर्ण है।
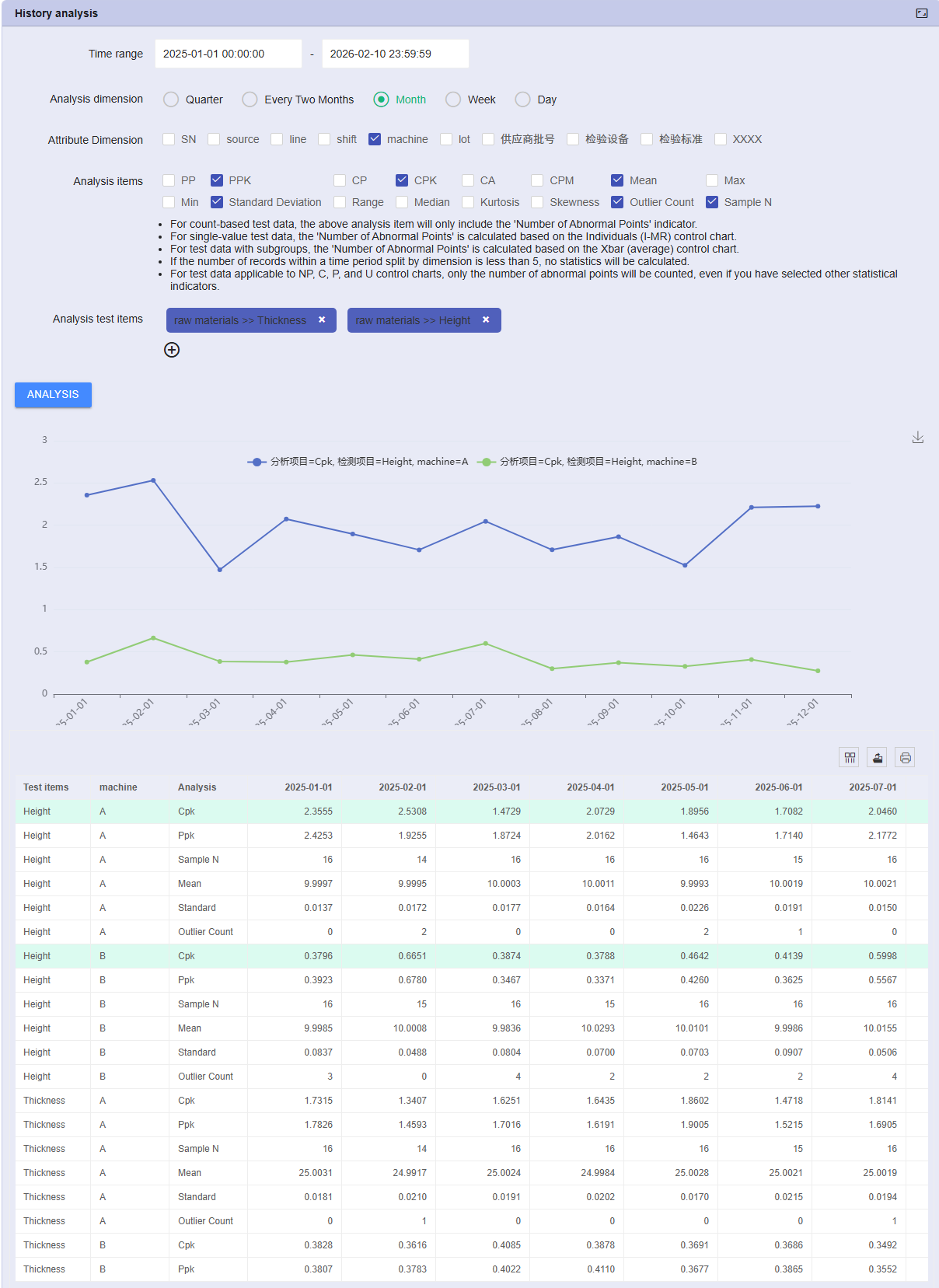
History Trend Analysis Engine
10 वस्तुओं के लिए वार्षिक गुणवत्ता परिवर्तनों को जल्दी कैसे ट्रैक करें? पारंपरिक रूप से, यह एक बुरा सपना है। NEXSPC में एक शक्तिशाली टाइम-सीरीज़ स्लाइसिंग इंजन है, जो दिनों के काम को सेकंड में बदल देता है। बस चक्र को परिभाषित करें, और सिस्टम स्वचालित रूप से मेट्रिक्स को साफ, विभाजित और एकत्रित करता है।
परिदृश्य: Q1 बनाम Q2 गुणवत्ता की तुलना करना, या मासिक CPK रुझान देखना। NEXSPC मैनुअल डेटा प्रोसेसिंग बाधाओं को समाप्त करता है। एक्सेल में निर्यात करने की कोई आवश्यकता नहीं है।
स्वचालित डेटा एकत्रीकरण: जब तक डेटा सिस्टम में है, चाहे वह एक वर्ष का हो या तीन वर्ष का, यह उसे तुरंत पकड़ लेता है।
बहु-परियोजना समानांतर विश्लेषण: एक साथ कई प्रमुख उत्पाद विशेषताओं (KPC) का चयन करने का समर्थन करता है। बैच ऐतिहासिक विश्लेषण चलाएँ।
परिदृश्य: विभिन्न प्रबंधन स्तरों के लिए विश्लेषण विवरण को अनुकूलित करें।
आइटम चुनें: उन एक या अधिक निरीक्षण वस्तुओं की जाँच करें जिनकी आपको परवाह है।
रेंज परिभाषित करें: प्रारंभ और समाप्ति समय निर्धारित करें (जैसे, 1 जनवरी, 2026 से 31 दिसंबर, 2026)।
स्लाइस चक्र: डेटा स्लाइसिंग ग्रैन्युलैरिटी चुनें। तिमाही, द्वि-माह, महीना, सप्ताह या दिन द्वारा ऑटो-स्प्लिटिंग का समर्थन करता है।
संकेतक चुनें: PPK, CPK, Ca (क्षमता सूचकांक), आउटलेयर, मीन, StdDev आदि जैसे KPI को स्वतंत्र रूप से मिलाएं।
परिदृश्य: नेतृत्व प्रस्तुतियों के लिए ठोस संख्यात्मक रिपोर्ट और सहज प्रवृत्ति लाइन चार्ट दोनों की आवश्यकता है।
विश्लेषण पूरा होने पर: सिस्टम तुरंत एक बहु-आयामी गुणवत्ता इतिहास सांख्यिकी तालिका उत्पन्न करता है।
संरचित रिपोर्टिंग: तालिका प्रत्येक अवधि के लिए CPK मान और आउटलेयर counts जैसे मेट्रिक्स का विवरण देती है।
ऑनलाइन ट्रेंड प्लॉटिंग: PPT के लिए स्क्रीनशॉट की आवश्यकता नहीं है। गतिशील प्रवृत्ति लाइन चार्ट उत्पन्न करने के लिए सीधे वेब तालिका में पंक्तियों का चयन करें।
परिदृश्य: PDCA चक्र को चलाने के लिए विश्लेषण परिणामों का उपयोग करें।
एक-क्लिक एक्सेल निर्यात: हम व्यक्तिगत स्वरूपण या संग्रह के लिए उत्पन्न सांख्यिकी तालिका को एक्सेल में निर्यात करने का समर्थन करते हैं।
उत्पादकता को मुक्त करें: इंजीनियरों को कम मूल्य वाले 'टेबल बनाने' से मुक्त करें ताकि वे डेटा के पीछे के कारणों पर ध्यान केंद्रित कर सकें।
Hypothesis Testing / T-Tests
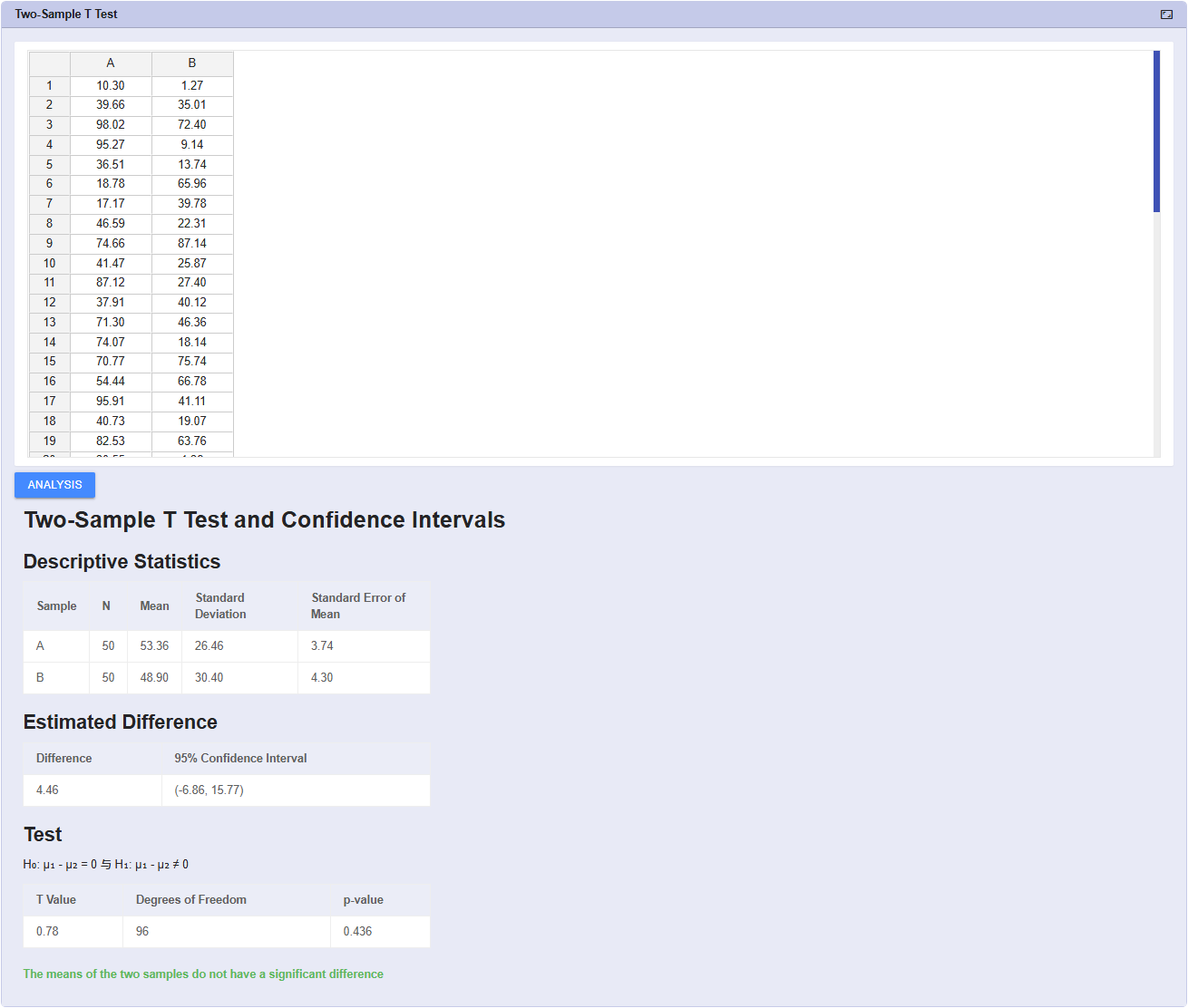
डेटा के साथ 'सुधार' साबित करें, किस्मत से नहीं। PDCA चक्र में, 'जांच' (Check) चरण महत्वपूर्ण है। NEXSPC सुधार से पहले और बाद के अंतरों की वैज्ञानिक रूप से तुलना करने के लिए पूर्ण-परिदृश्य T-Test उपकरण प्रदान करता है।
वन-सैंपल टी-टेस्ट (सत्यापित करें कि क्या माध्य शिफ्ट हुआ है) और टू-सैंपल टी-टेस्ट (मशीन ए बनाम बी, या पहले बनाम बाद की तुलना करें) का समर्थन करता है।
विश्वास अंतराल (Confidence Interval) चार्ट और बॉक्स प्लॉट को स्वचालित रूप से आउटपुट करता है। स्पष्ट रूप से बताता है कि क्या कोई महत्वपूर्ण अंतर है, 'झूठे सुधार' को समाप्त करता है।
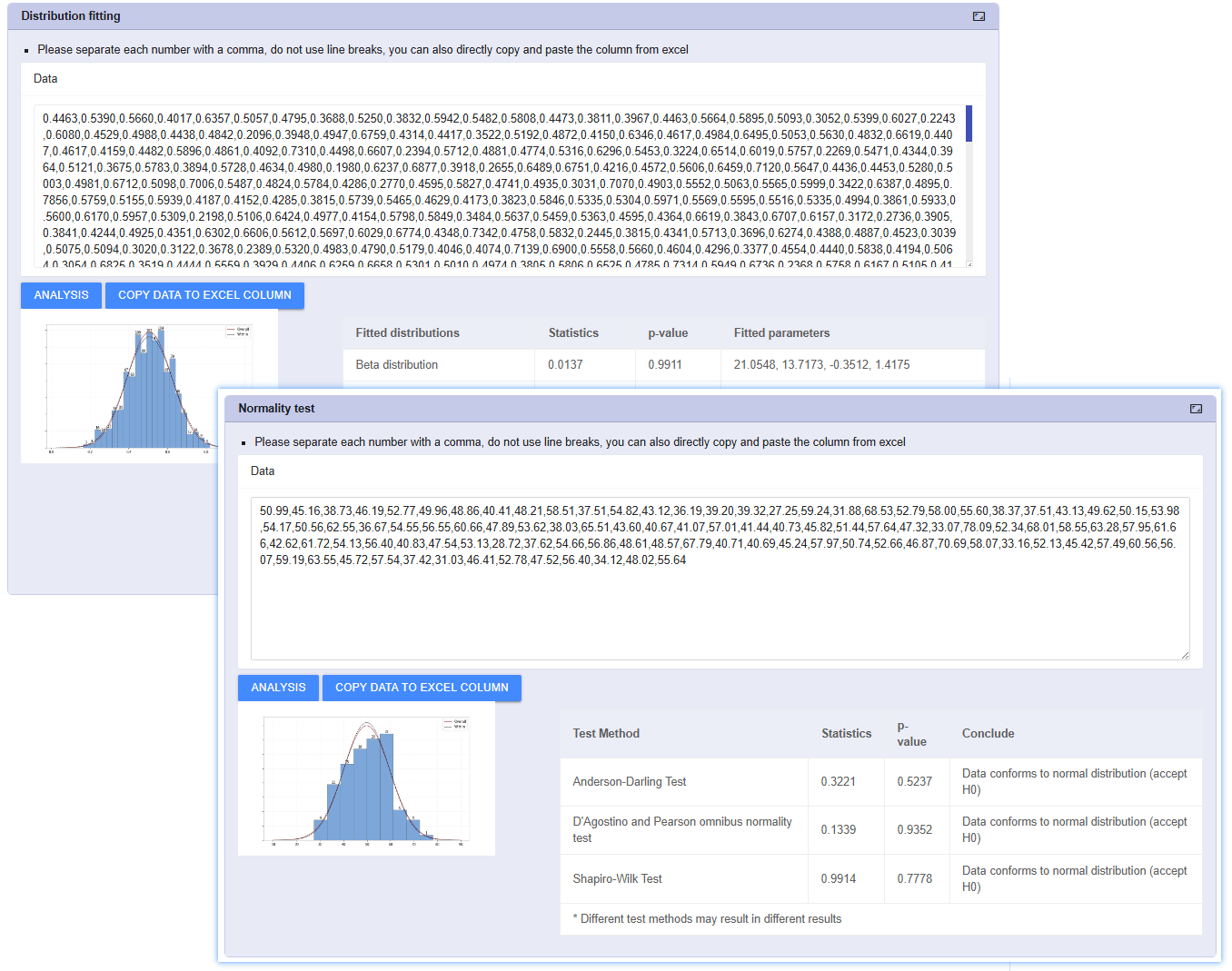
Distribution Fitting
वास्तविक दुनिया को प्रतिबिंबित करें और गैर-सामान्य डेटा का सटीक मूल्यांकन करें। सभी डेटा पूर्ण सामान्य वितरण का पालन नहीं करते हैं। जीवनकाल परीक्षण, समतलता और अशुद्धता सामग्री जैसे विषम डेटा के लिए, CPK सूत्रों का जबरदस्ती उपयोग करने से गंभीर गलत निर्णय होते हैं।
अंतर्निहित वीबुल, लॉग-सामान्य, घातीय मॉडल। सबसे उपयुक्त वितरण वक्र की सिफारिश करने के लिए एंडरसन-डार्लिंग परीक्षण स्वचालित रूप से चलाता है।
सर्वोत्तम-फिट मॉडल के आधार पर सटीक Ppk सूचकांकों की पुनर्गणना करता है, जो अर्धचालक और रसायन जैसे जटिल उद्योगों में विश्लेषण सटीकता सुनिश्चित करता है।
ANOVA & F-Test
परतों को वापस छीलें और कई हस्तक्षेपों के बीच भिन्नता के स्रोतों को अलग करें। जब गुणवत्ता कारक दो से अधिक हो जाते हैं (जैसे, 3 शिफ्ट या 4 मोल्ड की तुलना करना), तो साधारण टी-टेस्ट कम पड़ जाते हैं।
कई समूहों में महत्वपूर्ण औसत अंतरों को जल्दी से पहचानें। साधन के लिए मुख्य प्रभाव भूखंड उत्पन्न करता है।
साधन की तुलना करने से पहले, सत्यापित करें कि क्या दो डेटासेट का उतार-चढ़ाव आयाम (विचरण) सुसंगत है। उपकरण परिशुद्धता स्थिरता का आकलन करने के लिए महत्वपूर्ण।